优化DB2数据库的5个最佳实践
概述
结构化查询语言(SQL)对于关系型DBMS是把双刃剑,利弊参半。因为从关系型数据库检索任何数据都需要SQL,本文所要探讨的话题就是:不论是终端用户还是开发人员或是数据库管理员(DBA),他们将如何访问一个关系型数据库。当使用高效的SQL 时,系统会变得易于升级、灵活、 而且便于管理。当使用低效的SQL 时, 响应时间和程序运行时间都会延长,并且还会产生应用系统的中断。鉴于通常的数据库系统一般要花费90% 的处理时间用于从数据库检索数据,由此很明显的可以看出尽可能的保证SQL的高效是多么的重要。考察通常的SQL语句 问题譬如"SELECT * FROM"仅是冰山一角,我们将在本文中探讨其他容易确定的普遍的问题。需要记住的是, 检索得到同一数据的SQL 语句有很多种殊途同归的写法,所以不存在好的查询语句或是坏的查询语句,而只有满足适当需求的查询语句。各关系型数据库都有自己的方式来优化和执行查询语句。因此,各DBMS都拥有自己的最佳性能的查询技巧。本文将使用 Quest 软件中Quest Central for DB2 的例子和概述来集中讨论 DB2 for OS/390 和z/0S。
要是在十七年前,这张技巧单会更长,并且会包含对最小化的 SELECT 场景的矫正方法。每一个新版本的DB2 都会增加成千上万行的新代码,用以扩展智能优化,和查询重写及执行。例如,多年来一种被称为数据管理器的组件, 通常被提供作为"第一阶段处理"以增加它的过滤容量一百倍。另一组件是关系型数据服务器,通常被提供作为"第二阶段处理"来进行其主函数的查询重写和优化。另一关键组件就是基于当前的SQL,并使用存取路径以决定检索数据的DB2 优化器。DB2 优化器改善了每一个DB2 的版本, 考虑到另外的DB2目录中的统计, 可以提供新的和改善过的存取路径。图1显示了这些组件及其他更多的部分,并描述了DB2 如何处理数据或SQL的请求。这就是以下DB2 SQL性能技巧的来源。
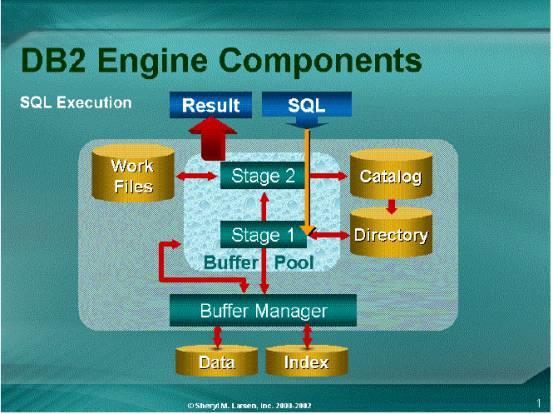
图1:DB2 Engine 和一些组件介绍
在这篇文章中,我们将回顾一些更具有代表性的SQL 问题,有更多的SQL方面的性能技巧超出了本篇文章描述的范围。像所有指导方针一样,所有这些技巧也会有一些例外。
技巧1: 核实是否提供了适当的统计
对于DB2 优化器来说,最重要的资源除了SELECT语句本身,就是DB2 目录中创建的统计。优化器基于众多的选择而使用这些统计。DB2 优化器为了查询而选择一条非最佳存取路径的主要原因,归结于无效的或缺失的统计。DB2优化器使用以下目录统计:

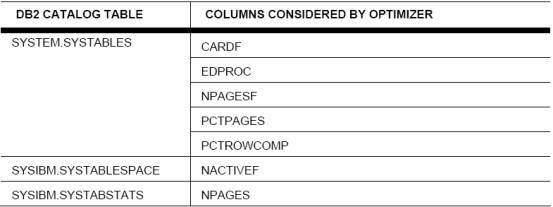
图2:DB2 优化器验证过的列和用来确定的存取路径
经常的执行"RUNSTATS"命令,用来更新DB2的目录统计,这样可以在特别繁忙的生产环境里中得到全貌。为了使执行"RUNSTATS"命令的影响最小化,可以考虑使用采样技术。即使取样10%也够了。另外"RUNSTATS"命令可以更新统计,DB2给您可以额外更新1,000 个条目的能力,以用于不均匀的分类统计。当心随着每一条目随着增量的增加,而涉及到对所有参考的绑定时间的影响。
假如当您缺少统计的时候您怎么知道呢? 当目录或使用工具不能提供这种功能的时候,您可以通过手工执行查询。 当前, DB2优化器不能给缺失的统计提供具体的警告。
技巧2: 尽可能的采用阶段1和阶段2 的谓词
不论是阶段1的数据管理器还是阶段2 的关系型数据服务器都将处理每一次查询。当您处理查询时,使用阶段1将会比使用阶段2有着巨大的性能优势。当谓词确定阶段1能够处理的时候,通常谓词会限制您只能使用阶段1查询。另外, 每一个谓词都会被检验评估是否比另一个谓词更有资袼作为索引路径。有一些谓词不能作为阶段1来处理,或是不符合索引的条件。关于您的查询是否可以被索引并且能够在阶段1被处理,理解这一点是很重要的。下面是文挡化的阶段1或Sargable(search + argument-able 谓词是一个可以由数据管理器来值的谓词)谓词:
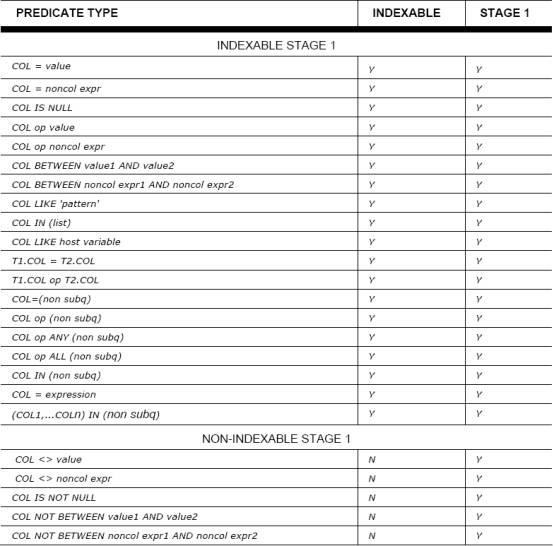
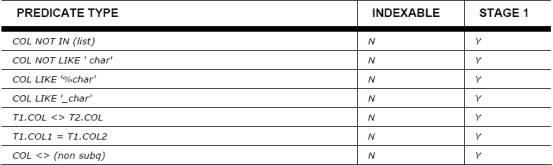
图3:通常用表单来确定谓词是否合格
还有一些谓词不能看作阶段1被文档化,因为他们不能总处于阶段1。加入表序列和查询重写也能够影响谓词被过滤掉的阶段。让我们通过例子查询来显示重写您的SQL的影响。
例子1:COL1 和COL1 之间的值
任何类型的谓词如不能被阶段1识别,就是阶段2。如下所示就是阶段2 谓词。然而, 重写可能促进对可索引阶段1的查询。
Value >= COL1 AND value <= COL2
这意味着, 优化器也许会在多个索引中选择一个匹配的索引来使用谓词。 没有重写, 谓词的剩余被当作阶段2 。
例子2: COL3 NOT IN (K,S,T)
如果可能,非可索引的阶段1 的谓词也应该被重写。例如,符合以上条件的是阶段1,但不是可索引的。括号里值的列表辨认什么与COL3 不相等。为了确定重写的可行性,辨认出那些COL3不相等的、更长和更不稳定的表单,就越不具有可行性。如果对面的(K, S, T) 是少于200的静态值,就值得输入额外的重写。促进阶段1 的条件对于可索引的阶段1,提供了其它匹配索引选择的优化器。既使一个可支持的索引在绑定时间不可利用, 重写也将确保查询具有索引访问的资格,并且此索引将在以后被创建。一旦一个索引被创建并与COL3合并, 重新绑定的事务也许可能获得匹配的索引访问, 那里的旧谓词将不会对重新绑定有影响。
技巧3: 仅选择需要的列
每一个被选择的列必须单独地被传回到调用程序,除非对整个的DCLGEN 定义有精确匹配的。这也可能依赖于您向所有列发出的请求,但是,真正的损失发生在需要排序的时候。每一个被SELECTed的列, 和重复的排序列,使得排序文件的宽度更宽。文件越长越宽,排序越慢。例如,100,000 个四字节的列可能在大约一秒的时间内完成排序。而只有10,000个五十字节的列可能在同样时间内完成排序。 实际的时间是非常依赖于硬件的。
这个规则的例外是"Disallow SELECT*",当几个处理需要一个表中行的不同的部分的时候。通过事务的整合, 一次取回所有行, 然后单独处理这些部分。
技巧 4: 选择唯一需要的行
越少的行被检索,查询将运行的越快。 符合要求的行不得不令自己在存储器中通过漫长之旅, 穿过缓冲池, 阶段1, 阶段2,可能的分类和转换,然后传递结果集到调用程序。数据库管理器管理所有的数据过滤;这对于检索一行是非常浪费的,测试在程序代码里的那一行,然后过滤掉那行。禁止程序自动过滤是一个必须强制执行的铁的规则。开发商可能选择使用程序代码执行所有或部分的数据操作或者他们可能选择使用SQL 。典型地是混合在一起。 已知的叙述显示,过滤器可能被放入DB2 engine里的程序代码,类似:
IF TABLE-COL4 > :VALUE
GET NEXT RESULT ROW
技巧 5: 使用常量和字面值,如果值在以后的3 年中不改变(对于静态查询)
DB2 优化器对所有不均匀的分类统计都充分的使用, 并为任何一个列统计提供了不同领域范围内的值,尤其当没有主机变量在谓词中被发现时, (WHERE COL5 >'X')。 主机变量的目的是使一个事务能适应一个可变化的变量;当一个用户请求输入这个值的时候是最经常被使用的。 主机变量不需要重新绑定一个程序,当这个变量每一次改变的时候。 这种可延伸性能得到优化器准确的耗费。 当主机变量刚被发现, (WHERE COL5 >:hv5), 优化器使用以下的图表来评估过滤器要素, 而不是使用目录统计:
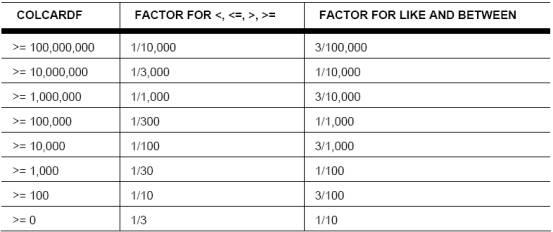
图 4:过滤器要素
列的基数性越高, 则谓词的过滤器要素就越低(保留部分行的预测) 。 多数时候,这种评估有助于优化器对适当存取路径的选取。然而, 有时谓词的过滤器要素远离实际。这就是通常需要对存取路径进行调优的时候。
解决方案
Quest Central for DB2是一个集成的控制台,可以提供核心功能,DBA (数据库管理员)需要执行他们日常的数据库管理任务, 空间管理, SQL调优和分析, 并且可以进行性能诊断监视。Quest Central for DB2 是由DB2 软件专家撰写的,并且提供具丰富的功能,以利于视图化的用户界面,并且支持在Unix, Linux,和windows主机上运行DB2 数据库。DB2 的客户不再被要求用独立的工具维护和使用他们的主机和分布式的DB2 系统。
Quest Central 的SQL调优组件提供一个完整的SQL 调优环境。 Quest Central是唯一可以提供完整的SQL 调优环境的针对DB2可用的产品。这个环境包括以下部分:
1: 调优实验室:通过场景的使用,一个单独的SQL 语句能够被改进很多次。然后这些场景能够立刻被比较以确定哪个SQL 语句提供了最有效率的存取路径。
2. 比较: 您立刻可以看出对于SQL 语句修改的性能改变效果。 由于比较多个场景, 您能看到对CPU 的效果, 消耗的时间, I/O 和其他更多的统计。 另外数据的比较将保证您的SQL 语句返回相同的数据子集。
3. 建议:由SQL 调优组件提供的建议,将会发现所有的在白皮书指定的条件等等。 另外, 如果一个新场景可以利用,SQL 调优组件甚至将会重写SQL ,并综合选择的建议。
4. 存取路径和对应的统计:在SQL的上下文中,对于DB2存取路径,所有适合的统计应被显示出来。 采取推测以设法理解为什么选择一个特殊的存取计划。
Quest Central for DB2 健壮的功能显现了上述SQL 调优中的技巧以及更多。 这篇白皮书剩余的部分将证明 Quest Central 是由更丰富和更透彻的知识恰当的组成的。 Quest Central 不仅可以提高您的SQL语句效率,更可以帮助您全面的提升数据库的性能。上面描述的各种调优技巧都被Quest Central所包括。
解决的技巧 1: 核实特定提供的统计
一旦一条SQL 语句在Quest Central中被描述,建议栏会提供一整套建议,包括当没有RUNSTATS时也可以发现的能力。Quest Central 一直以坚定的决心来探究这类建议。每一条建议都有相对应的"建议操作"。这种建议操作会指导如何矫正建议发现的问题。这将会打开一个新的场景由被重写的SQL或以促进对象分析的脚本组成。在这个例子中, 建议显示, 统计的缺失和相对应的建议操作将建立一个脚本,它包含RUNSTATS 命令,为了在建议操作的窗口中选择任何一个对象。
图6: SQL 调优的组件鉴别所有对象缺失的统计, 并且能够生成必要的命令对所有选择对象的统计进行更新。
另外, Quest Central Space 的管理能够自动的收集、维护和检验在表空间里的统计及表和索引等级。以下的例子显示了在数据库里所有表空间里的统计检验报告。
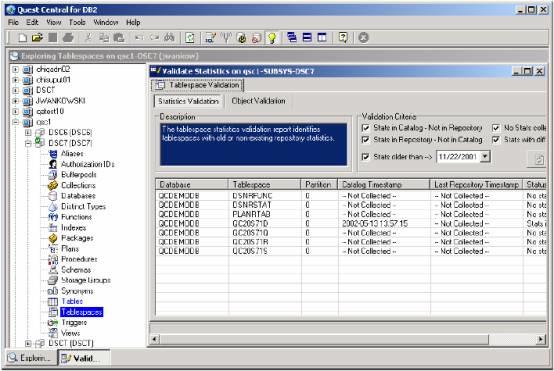
图7: Quest Central提供了一套容易使用的图形界面,以促进RUNSTATS 处理的自动化。
解决的技巧 2: 尽可能的提升阶段2 和 阶段1的谓词
SQL 的调优组件将列出所有的谓词并指出那些谓词是否是"Sargable" 或"Non-Sargable" 。 另外, 各个谓词都将被检查,以确定它是否具有索引存取的资袼。 这种单独的建议可以解决响应时间的问题和在谓词重写的期间内得到某些成果。在下面的例子中,一条查询被看作non-sargable 和non-indexable (阶段2) 。 这条最初的查询被输入在一个谓词间。 一个新场景被打开了并且谓词被重写使用大于, 小于符号。 这种比较确定了查询重写对性能方面的影响。
图8: Query that is non-indexable and non-sargable(stage 2)
一个新场景被创建并且查询被重写在列值中使用" a> = "和"a< = "。 注意,谓词现在是可索引的和sargable 。 记住以上的信息, 谓词现在将由数据管理器(阶段1)处理,以减少这次查询的潜在响应时间。
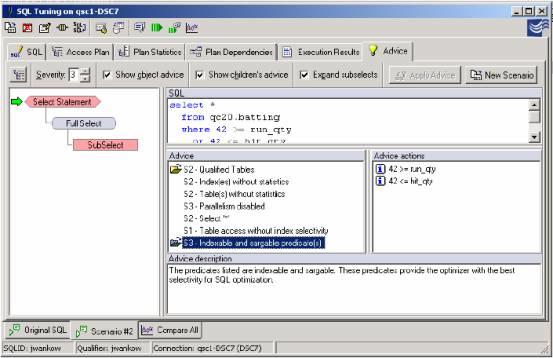
图9: 查询是indexable 和sargable (阶段1)
随后可以使用比较工具来比较他们和 "<>"之间的性能, 会发现"<>"更有效的减少消耗的时间。

图10: 耗时减半
解决的技巧 3:选择唯一需要的列
SQL 调优的特点不仅是相对于使用"SELECT*"的建议, 更提供一个事半功倍的可以令产品自动重写SQL 的特点。 建议和相对应的建议操作将提供重写您SQL的能力,简单地检查想要的列并选择"apply advice"按钮, SQL调优将用被选择的列替换"*"。

图11: "apply advice" 的特点是将重写SQL ,并重视选择的建议操作。
解决的技巧 4:选择唯一需要的行
越少的行被检索, 查询将运行的越快。使用Quest Central能比较您最初的SQL 相对于选择较少行但相同的SQL 语句。使用多个场景和利用比较特点, 比较那些立刻显示发生变化的性能影响的场景。 在以下例子中,两张表单的加入,产生了一个有意义的结果集。 由于加入了"Fetch First 1Row Only'"执行时间显著的减少了。
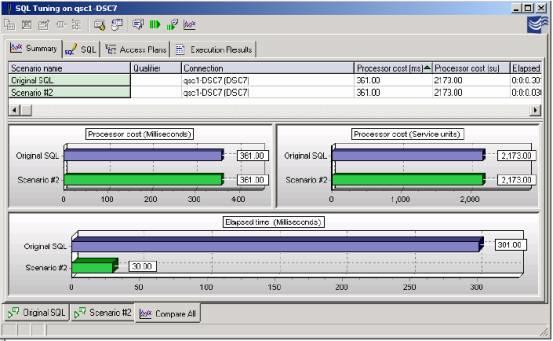
图12: 为了减少行数而修改一个SELECT语句, 用来比较确认性能的受益
解决的技巧 5:使用常量和字面值,如果值在以后的3 年中不改变(对于静态查询)
在这个例子中,让我们进行一个基于Win2K 平台的DB2测试。 当使用主机变量时, DB2 优化器无法预测谓词过滤的值。没有这个值, DB2 将默认并使用上面列出的默认的过滤器要素。Quest Central SQL 调优将一直显示过滤器要素用以帮助了解有多少列将被过滤。
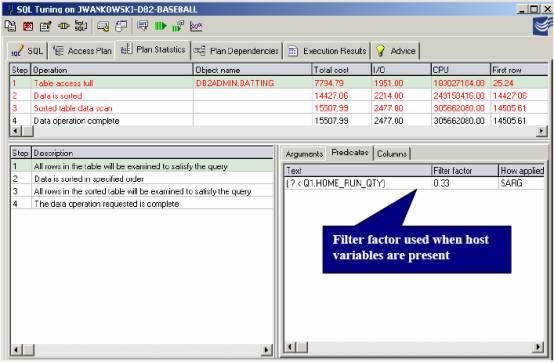
图13: Quest Central显示每个谓词的过滤器要素
(北京铸锐数码科技有限公司 www.InnovateDigital.com)